11 releases
| 0.1.10 | May 20, 2024 |
|---|---|
| 0.1.9 | Apr 15, 2024 |
| 0.1.8 | Jun 18, 2023 |
| 0.1.7 | Mar 13, 2023 |
| 0.1.4 | Nov 1, 2022 |
#70 in Command line utilities
27 downloads per month
91KB
981 lines
Ksunami
Waves of Kafka Records!
What's Ksunami?
Ksunami is a command-line tool to produce a constant, configurable, cyclical stream of (dummy) records against a Kafka Cluster Topic.
If you are experimenting with scalability and latency against Kafka, and are looking for ways to reproduce a continues stream of records, following a specific traffic pattern that repeats periodically, Ksunami is the tool for you.
Ksunami offers a way to set up the production of records, expressing the scenario as a sequence of "phases" that repeat indefinitely. Records content is configurable but random: the purpose of the tool is to help with performance and scalability testing of your infrastructure.
Features
- Production described in 4 "phases" that repeat in circle:
min,up,maxanddown - All phases are configurable in terms of seconds (duration) and records per second (workload)
upanddowncan be one of many transitions, each with a specific "shape" (ex.linear,ease-in,spike-out, ...)- Records
keyandpayloadare configurable with fixed, from-file and randomly-generated values - Records headers can be added to each record
- Kafka producer is fully configurable, including selecting a partitioner
- Built on top of the awesome librdkafka
Getting started
To install ksunami, currently you need to compile it yourself. You need the Rust Toolchain
and then run:
$ cargo install ksunami
Note We are working to provide binary releases (i#13) and an homebrew (i#14) installation.
In Docker
Ksunami is now available as a Docker Image: kafkesc/ksunami on the Docker Hub registry.
Both linux/amd64 and linux/arm64 images are available, based on Debian slim images.
The ENTRYPOINT is the ksunami binary itself, so you can just pass arguments to the container execution.
Usage
Thanks to clap, Ksunami provides out of the box support for compact and extended usage instructions.
Compact: ksunami -h
Produce constant, configurable, cyclical waves of Kafka Records
Usage: ksunami [OPTIONS] --brokers <BOOTSTRAP_BROKERS> --topic <TOPIC> --min <REC/SEC> --max <REC/SEC>
Options:
-b, --brokers <BOOTSTRAP_BROKERS> Initial Kafka Brokers to connect to (format: 'HOST:PORT,...')
--client-id <CLIENT_ID> Client identifier used by the internal Kafka Producer [default: ksunami]
--partitioner <PARTITIONER> Partitioner used by the internal Kafka Producer [default: consistent_random] [possible values: random, consistent,
consistent_random, murmur2, murmur2_random, fnv1a, fnv1a_random]
-c, --config <CONF_KEY:CONF_VAL> Additional configuration used by the internal Kafka Producer (format: 'CONF_KEY:CONF_VAL')
-t, --topic <TOPIC> Destination Topic
-k, --key <KEY_TYPE:INPUT> Records Key (format: 'KEY_TYPE:INPUT').
-p, --payload <PAYLOAD_TYPE:INPUT> Records Payload (format: 'PAYLOAD_TYPE:INPUT').
--partition <PARTITION> Destination Topic Partition
--head <HEAD_KEY:HEAD_VAL> Records Header(s) (format: 'HEAD_KEY:HEAD_VAL')
--min <REC/SEC> Minimum amount of records/sec
--min-sec <SEC> How long to produce at minimum records/sec, before ramp-up [default: 60]
--max <REC/SEC> Maximum amount of records/sec
--max-sec <SEC> How long to produce at maximum records/sec, before ramp-down [default: 60]
--up <TRANSITION_TYPE> Ramp-up transition from minimum to maximum records/sec [default: linear] [possible values: none, linear, ease-in, ease-out,
ease-in-out, spike-in, spike-out, spike-in-out]
--up-sec <SEC> How long the ramp-up transition should last [default: 10]
--down <TRANSITION_TYPE> Ramp-down transition from maximum to minimum records/sec [default: none] [possible values: none, linear, ease-in, ease-out,
ease-in-out, spike-in, spike-out, spike-in-out]
--down-sec <SEC> How long the ramp-down transition should last [default: 10]
-v, --verbose... Verbose logging.
-q, --quiet... Quiet logging.
-h, --help Print help information (use `--help` for more detail)
-V, --version Print version information
Extended: ksunami --help
Produce constant, configurable, cyclical waves of Kafka Records
Usage: ksunami [OPTIONS] --brokers <BOOTSTRAP_BROKERS> --topic <TOPIC> --min <REC/SEC> --max <REC/SEC>
Options:
-b, --brokers <BOOTSTRAP_BROKERS>
Initial Kafka Brokers to connect to (format: 'HOST:PORT,...').
Equivalent to '--config=bootstrap.servers:host:port,...'.
--client-id <CLIENT_ID>
Client identifier used by the internal Kafka Producer.
Equivalent to '--config=client.id:my-client-id'.
[default: ksunami]
--partitioner <PARTITIONER>
Partitioner used by the internal Kafka Producer.
Equivalent to '--config=partitioner:random'.
[default: consistent_random]
Possible values:
- random:
Random distribution
- consistent:
CRC32 hash of key (Empty and NULL keys are mapped to single partition)
- consistent_random:
CRC32 hash of key (Empty and NULL keys are randomly partitioned)
- murmur2:
Java Producer compatible Murmur2 hash of key (NULL keys are mapped to single partition)
- murmur2_random:
Java Producer compatible Murmur2 hash of key (NULL keys are randomly partitioned): equivalent to default partitioner in Java Producer
- fnv1a:
FNV-1a hash of key (NULL keys are mapped to single partition)
- fnv1a_random:
FNV-1a hash of key (NULL keys are randomly partitioned)
-c, --config <CONF_KEY:CONF_VAL>
Additional configuration used by the internal Kafka Producer (format: 'CONF_KEY:CONF_VAL').
To set multiple configurations keys, use this argument multiple times. See: https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md.
-t, --topic <TOPIC>
Destination Topic.
Topic must already exist.
-k, --key <KEY_TYPE:INPUT>
Records Key (format: 'KEY_TYPE:INPUT').
The supported key types are:
* 'string:STR': STR is a plain string
* 'file:PATH': PATH is a path to an existing file
* 'alpha:LENGTH': LENGTH is the length of a random alphanumeric string
* 'bytes:LENGTH': LENGTH is the length of a random bytes array
* 'int:MIN-MAX': MIN and MAX are limits of an inclusive range from which an integer number is picked
* 'float:MIN-MAX': MIN and MAX are limits of an inclusive range from which a float number is picked
-p, --payload <PAYLOAD_TYPE:INPUT>
Records Payload (format: 'PAYLOAD_TYPE:INPUT').
The supported payload types are:
* 'string:STR': STR is a plain string
* 'file:PATH': PATH is a path to an existing file
* 'alpha:LENGTH': LENGTH is the length of a random alphanumeric string
* 'bytes:LENGTH': LENGTH is the length of a random bytes array
* 'int:MIN-MAX': MIN and MAX are limits of an inclusive range from which an integer number is picked
* 'float:MIN-MAX': MIN and MAX are limits of an inclusive range from which a float number is picked
--partition <PARTITION>
Destination Topic Partition.
If not specified (or '-1'), Producer will rely on the Partitioner. See the '--partitioner' argument.
--head <HEAD_KEY:HEAD_VAL>
Records Header(s) (format: 'HEAD_KEY:HEAD_VAL').
To set multiple headers, use this argument multiple times.
--min <REC/SEC>
Minimum amount of records/sec
--min-sec <SEC>
How long to produce at minimum records/sec, before ramp-up
[default: 60]
--max <REC/SEC>
Maximum amount of records/sec
--max-sec <SEC>
How long to produce at maximum records/sec, before ramp-down
[default: 60]
--up <TRANSITION_TYPE>
Ramp-up transition from minimum to maximum records/sec
[default: linear]
Possible values:
- none: Immediate transition, with no in-between values
- linear: Linear transition, constant increments between values
- ease-in: Slow increment at the beginning, accelerates half way through until the end
- ease-out: Fast increment at the beginning, decelerates half way through until the end
- ease-in-out: Slow increment at the beginning, accelerates half way, decelerates at the end
- spike-in: Fastest increment at the beginning, slowest deceleration close to the end
- spike-out: Slowest increment at the beginning, fastest acceleration close to the end
- spike-in-out: Fastest increment at the beginning, slow half way, fastest acceleration close to the end
--up-sec <SEC>
How long the ramp-up transition should last
[default: 10]
--down <TRANSITION_TYPE>
Ramp-down transition from maximum to minimum records/sec
[default: none]
Possible values:
- none: Immediate transition, with no in-between values
- linear: Linear transition, constant increments between values
- ease-in: Slow increment at the beginning, accelerates half way through until the end
- ease-out: Fast increment at the beginning, decelerates half way through until the end
- ease-in-out: Slow increment at the beginning, accelerates half way, decelerates at the end
- spike-in: Fastest increment at the beginning, slowest deceleration close to the end
- spike-out: Slowest increment at the beginning, fastest acceleration close to the end
- spike-in-out: Fastest increment at the beginning, slow half way, fastest acceleration close to the end
--down-sec <SEC>
How long the ramp-down transition should last
[default: 10]
-v, --verbose...
Verbose logging.
* none = 'WARN'
* '-v' = 'INFO'
* '-vv' = 'DEBUG'
* '-vvv' = 'TRACE'
Alternatively, set environment variable 'KSUNAMI_LOG=(ERROR|WARN|INFO|DEBUG|TRACE|OFF)'.
-q, --quiet...
Quiet logging.
* none = 'WARN'
* '-q' = 'ERROR'
* '-qq' = 'OFF'
Alternatively, set environment variable 'KSUNAMI_LOG=(ERROR|WARN|INFO|DEBUG|TRACE|OFF)'.
-h, --help
Print help information (use `-h` for a summary)
-V, --version
Print version information
Examples
Here are some examples of things you can do with Ksunami. It's not an exhaustive collection, but it can hopefully give you a good starting point, and maybe some inspiration.
Note Parameters in the examples are expressed as
{{ PARAMETER_NAME }}.
Connect to Kafka cluster requiring SASL_SSL
$ ksunami \
--brokers {{ BOOTSTRAP_BROKERS or BROKER_ENDPOINT }} \
--config security.protocol:SASL_SSL \
--config sasl.mechanisms=PLAIN \
--config sasl.username:{{ USERNAME or API_KEY }} \
--config sasl.password:{{ PASSWORD or API_SECRET }} \
--topic {{ TOPIC_NAME }} \
...
Min/Max log verbosity
# Set logging to TRACE level
$ ksunami ... -vvv
# Set logging to OFF level
$ ksunami ... -qq
# Set logging to ERROR level, via env var
KSUNAMI_LOG=ERROR ksunami ...
Low rec/sec, but spike of 1000x once-a-day, lasting 60 seconds
$ ksunami \
--topic {{ ONCE_A_DAY_SPIKE_TOPIC }} \
... \
--min-sec 86310 \ # i.e. 24h - 90s
--min 10 \ # most of the day, this topics sees 10 rec/sec
\
--up-sec 10 \ # transitions from min to max within 10 sec
--up spike-in \ # sudden jump: 10k rec/sec
\
--max-sec 60 \ # a spike of just 60s
--max 10000 \ # producing at 10k rec/sec
\
--down-sec 20 \ # transitions from max to min within 20 sec
--down spike-out \ # sudden drop: back to just 10 rec/sec
...
Records in a wavy-pattern over the 24h cycle
$ ksunami \
--topic {{ WAVY_TOPIC }} \
... \
--min-sec 21600 \ # first quarter of the day
--min 1000 \ # 1k rec/sec
\
--up-sec 21600 \ # second quarter of the day
--up ease-in-out \ # stable rise
\
--max-sec 21600 \ # third quarter of the day
--max 3000 \ # 3k rec/sec
\
--down-sec 21600 \ # fourth quarter of the day
--down ease-in-out \ # stable decline
...
Produce to random partitions , regardless of key
$ ksunami \
--topic {{ RANDOMLY_PICKED_PARTITION_TOPIC }} \
... \
--partitioner random
Produce records with random alphanumeric key, but fixed payload from file
$ ksunami \
--topic {{ RANDOM_KEYS_FIXED_PAYLOADS_TOPIC }} \
... \
--key alpha:{{ RANDOM_ALPHANUMERIC_STRING_LENGTH }} \
--payload file:{{ PATH_TO_LOCAL_FILE }} \
...
Production switches from min to max (and back) without transition
$ ksunami \
--topic {{ NO_TRANSITON_TOPIC }} \
... \
--min-sec 120 \
--min 100 \
\
--up none \ # switch from min to max after 120s
\
--max-sec 60 \
--max 1000 \
\
--down none \ # switch from max to min after 60s
...
Core concepts
The 4 phases
Ksunami is designed around the idea that the user has a specific "workload pattern" that they want to reproduce against their Kafka cluster. It might be steady/stable and never changing, or it can be a regular flux of records, interleaved with dramatic spikes that happen at regular intervals. Or it can be that you have a new customer that will bring lots more traffic to your Kafka cluster.
We have elected to describe such a workload in 4 phases, min, up, max, down, that repeat indefinitely:
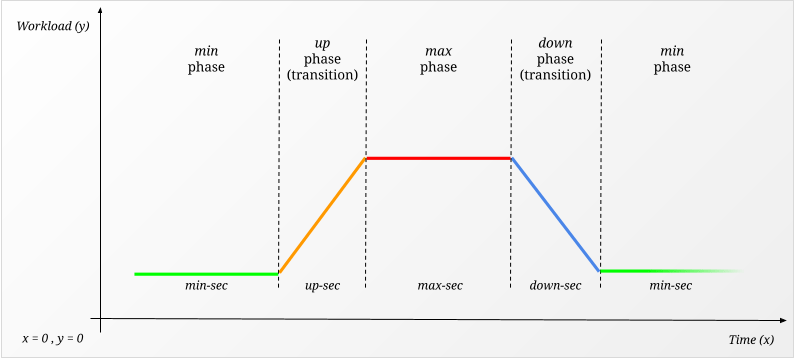
Each phase is associated with a *-sec duration argument, to choose how long each should be.
Additionally, min and max are associated with an amount of records/sec (i.e. workload), while up and down
are associated with a transition.
Transitions
When moving between min and max phases, the phases up and down are traversed. Those phases are "transitional":
Ksunami allows to describe "how" the transition between the phases happens. Each transition has a name,
and corresponds to a Cubic Bézier curve:
leaving to the reader to learn about this class of curves,
the short story is that Cubic Bézier curves describe the interpolation across 4 control points, P0, P1, P2, P3.
Imagine we want to plot an up transition between the min and max phases, on a cartesian plane.
Time is expressed by x, and we consider the interval x = [0..1] as start and end of the transition.
The volume of records produced is instead expressed by y, also considered in the interval y = [0..1].
Given this premise, P0=(0,0) and P3=(1,1) represent the start and end of the up transition;
P0=(0,1) and P3=(1,0) represent instead the start and end of the down transition.
Our transition curve is encased in the bounding box (0,0), (1,0), (1,1), (0,1), and we can describe various kinds of
curves, by placing P1 and P2 within this bounding box. The following is the current list of transition name
that Ksunami supports, plotted both for the up and down phases:
| Transition | --up <TRANSITION_TYPE> |
--down <TRANSITION_TYPE> |
|---|---|---|
none |
- | - |
linear |
||
ease-in |
||
ease-out |
||
ease-in-out |
||
spike-in |
||
spike-out |
||
spike-in-out |
Please note: in the pictures above P0 and P3 don't change, but all variations are generated by moving P1 and P2.
Yes! It's possible to define additional variations, by picking new P1 and P2 points,
and adding those to a new value in the Transition enum. PRs welcome.
Configuration in depth
To begin, start by giving the usage section a look. If that is not enough, in this section we go more in depth into the most important configuration aspect of Ksunami.
Configuring the Producer
Additional to the obvious -b, --brokers for the bootstrap brokers, and --client-id for the client identifier,
it's possible to fine tune the Provider via --partitioner and -c, --config.
Partitioner
Possible values for the --partitioner argument are:
| Partitioner name | Description |
|---|---|
random |
Random distribution |
consistent |
CRC32 hash of key (Empty and NULL keys are mapped to single partition) |
consistent_random (default) |
CRC32 hash of key (Empty and NULL keys are randomly partitioned) |
murmur2 |
Java Producer compatible Murmur2 hash of key (NULL keys are mapped to single partition) |
murmur2_random |
Java Producer compatible Murmur2 hash of key (NULL keys are randomly partitioned): equivalent to default partitioner in Java Producer |
fnv1a |
FNV-1a hash of key (NULL keys are mapped to single partition) |
fnv1a_random |
FNV-1a hash of key (NULL keys are randomly partitioned) |
NOTE: Ksunami, being based on librdkafka, offers "only" the partitioners provided by said library.
For example, to use a purely random partitioner:
$ ksunami ... --partitioner random ...
Additional configuration
As per -c,--config, all the values supported librdkafka
are supported by Ksunami's producer.
For example, to set a 200ms producer lingering and to limit the number of producer send retries to 5:
$ ksunami ... -c linger.ms:200 ... --config message.send.max.retries:5 ...
Records: destination and content
You can configure the content of each record produced by Ksunami:
-t, --topic <TOPIC>: the destination topic to send the record to-k, --key <KEY_TYPE:INPUT>(optional): the key of the record-p, --payload <PAYLOAD_TYPE:INPUT>(optional): the payload of the record--partition <PARTITION>(optional): the specific partition inside the destination topic--head <HEAD_KEY:HEAD_VAL>(optional): one (or more) header(s) to decorate the record with
While for --topic, --partition and --head the input is pretty self-explanatory, --key and --payload support
a richer set of options.
Supported key and payload types
| Format | Description |
|---|---|
string:STR |
STR is a plain string |
file:PATH |
PATH is a path to an existing file |
alpha:LENGTH |
LENGTH is the length of a random alphanumeric string |
bytes:LENGTH |
LENGTH is the length of a random bytes array |
int:MIN-MAX |
MIN and MAX are limits of an inclusive range from which an integer number is picked |
float:MIN-MAX |
MIN and MAX are limits of an inclusive range from which a float number is picked |
This allows to have a degree of flexibility to the content that is placed inside records.
For example, to produce records where the key is an integer between 1 and 1000 and the payload is a random sequence of 100 bytes:
$ ksunami ... --key int:1-1000 --payload bytes:100
Records: amount and duration
As seen above when we introduced the 4 phases, Ksunami sees a workload pattern as a set of durations, workload volume and transitions.
Min and Max
The min and max phases represent the range of workload that a user wants to describe, and once setup, Ksunami will
cyclically go from min to max to min and so forth. The workload is expressed as records/sec, and the duration of
each phase in seconds.
Why seconds? Because it's small enough to describe any meaningful Kafka workload. Using a smaller unit would have yielded no real benefit. And using a larger unit, would lead to too coarse workload description.
The arguments used to configure min and max:
| Argument | Description | Default |
|---|---|---|
--min <REC/SEC> |
Minimum amount of records/sec | |
--min-sec <SEC> |
How long to produce at minimum records/sec, before ramp-up | 60 |
--max <REC/SEC> |
Maximum amount of records/sec | |
--max-sec <SEC> |
How long to produce at maximum records/sec, before ramp-down | 60 |
(Ramping) Up and Down
Again, as seen above, between the min and max phases there are 2 transitional phases: up and down.
They exist to describe the mutation of workload, as time progresses.
Ksunami offers a collection of transitions, and they are provided as arguments: Ksunami takes care
of taking the [0..1] curves shown above, and transpose them to the actual records/sec workload the user is after.
The arguments used to configure up and down:
| Argument | Description | Default |
|---|---|---|
--up <TRANSITION_TYPE> |
Ramp-up transition from minimum to maximum records/sec | linear |
--up-sec <SEC> |
How long the ramp-up transition should last | 10 |
--down <TRANSITION_TYPE> |
Ramp-down transition from maximum to minimum records/sec | none |
--down-sec <SEC> |
How long the ramp-down transition should last | 10 |
Log verbosity
Ksunami follows the long tradition of -v/-q to control the verbosity of it's logging:
| Arguments | Log verbosity level | Default |
|---|---|---|
-qq... |
OFF |
|
-q |
ERROR |
|
| none | WARN |
x |
-v |
INFO |
|
-vv |
DEBUG |
|
-vvv... |
TRACE |
It uses log and env_logger,
and so logging can be configured and fine-tuned using the Environment Variable KSUNAMI_LOG.
Please take a look at env_logger doc for
more details.
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Thanks
- Thanks to this page on Desmos Graphing Calculator, for providing an easy way to plot Cubic Bézier curves.
- Thanks to flo_curves for providing an easy Rust crate to manipulate Bézier curves.
- Thanks to librdkafka for being an awesome Kafka library, used by pretty much all Kafka clients out there, and thanks to the Rust binding rdkafka.
- Thanks to clap, for being the awesome-est CLI argument parser in existence.
Dependencies
~37–51MB
~1M SLoC