1 unstable release
Uses old Rust 2015
| 0.1.3 | Aug 15, 2018 |
|---|---|
| 0.1.2 |
|
| 0.1.1 |
|
| 0.1.0 |
|
#9 in #fabric
48 downloads per month
255KB
7.5K
SLoC
deploy
![]()
![]()
![]()
Deploy is runtime for Rust (nightly) that aides in the writing, debugging and deployment of distributed programs. Here's an example of such a program:
extern crate serde;
#[macro_use]
extern crate serde_derive;
extern crate deploy;
use deploy::*;
fn main() {
init(Resources::default());
let mut total = 0;
for index in 0..10 {
let greeting = format!("hello worker {}!", index);
let worker_arg = WorkerArg{index,greeting};
let pid = spawn(worker, worker_arg, Resources::default()).expect("Out of resources!");
let receiver = Receiver::<usize>::new(pid);
total += receiver.recv().unwrap();
}
println!("total {}!", total);
}
#[derive(Serialize,Deserialize)]
struct WorkerArg {
index: usize,
greeting: String
}
fn worker(parent: Pid, worker_arg: WorkerArg) {
println!("{}", worker_arg.greeting);
let sender = Sender::<usize>::new(parent);
sender.send(worker_arg.index*100).unwrap();
}
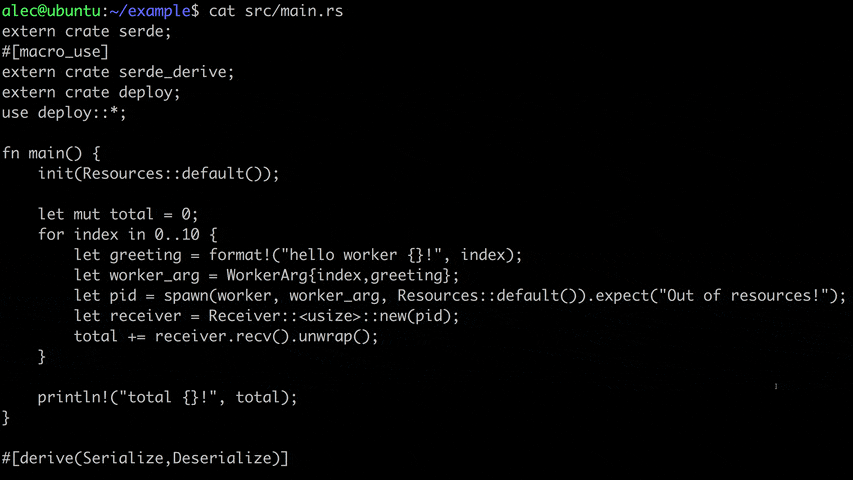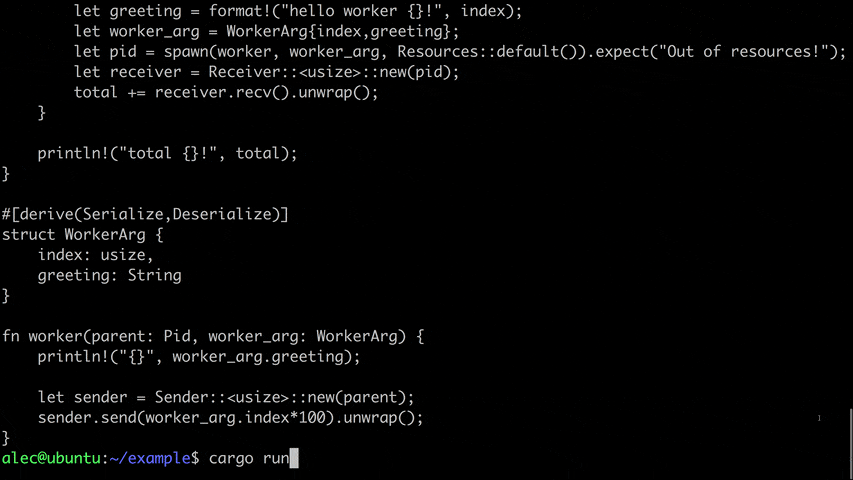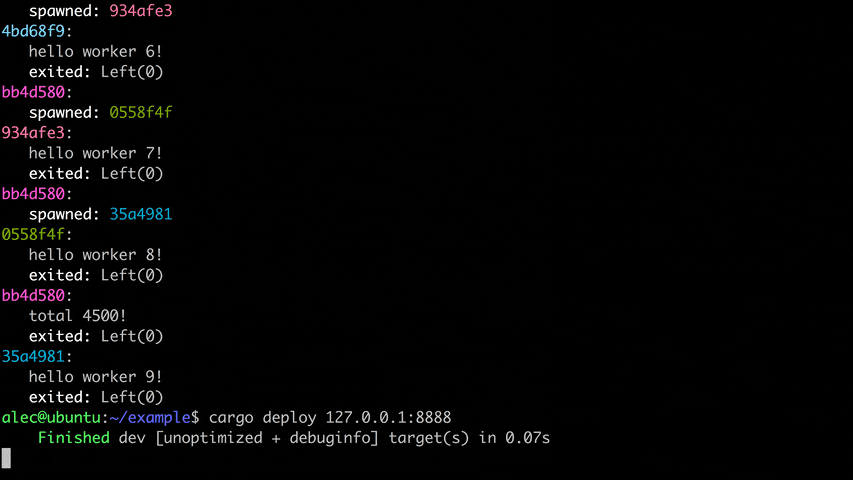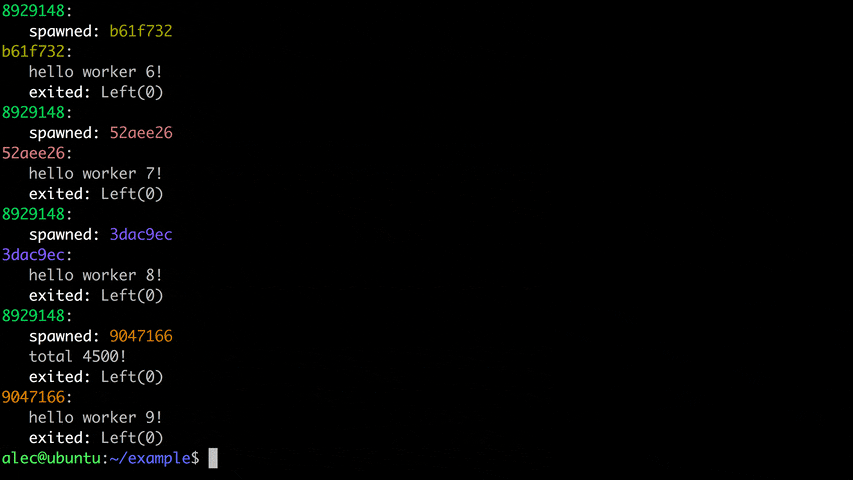
There are two components to Deploy:
- a library of functions that enable you to
spawn()processes, andsend()andrecv()between them - for when you want to run across multiple servers, a distributed execution fabric, plus the
deploycommand added to cargo to deploy programs to it.
Both output to the command line as show above – the only difference is the latter has been forwarded across the network.
Deploy is still nascent – development and testing is ongoing to bring support to macOS and Windows (currently it's Linux only) and reach a level of maturity sufficient for production use.
The primary efforts right now are on testing, documentation, refining the API (specifically error messages and usability of select()), and porting to macOS and Windows.
Features
Deploy takes care of:
spawn()to distribute processes with defined memory and CPU resource requirements to servers with available resources- Best-effort enforcement of those memory and resource requirements to avoid buggy/greedy processes starving others
- Channels between processes over TCP, with automatic setup and teardown
- Asynchronous (de)serialisation of values sent/received over channels (leveraging
serdeandlibfringe) select()to select over receivability/sendability of channels- Integration with
futures, thereby compatible withtokio - Powered by a background thread running an efficient edge-triggered epoll loop
- Ensuring data is sent and acked before process exit to avoid connection resets and lost data (leveraging
atexitandTIOCOUTQ) - Addressing: all channels are between cluster-wide
Pids, rather than(ip,port)s - Performant: designed to bring minimal overhead above the underlying OS
What's it for
Deploy makes it easier to write a distributed program. Akin to MPI, it abstracts away Berkeley sockets, letting you focus on the business logic rather than the addressing, connecting, multiplexing, asynchrony, eventing and teardown. Unlike MPI, it has a sane, modern, concise interface, that handles (de)serialisation using serde, offers powerful async building blocks like select(), and integrates with frameworks like tokio.
How it works
There are two execution modes: running normally with cargo run and deploying to a cluster with cargo deploy. We'll discuss the first, and then cover what differs in the second.
Every process has a monitor process that capture's the process's output, and calls waitpid on it to capture the exit status (be it exit code or signal). This is set up by forking upon process initialisation, parent being the monitor and the child going on to run the user's program. It captures the output by replacing file descriptors 0,1,2 (which correspond to stdin, stdout and stderr) with pipes, such that when the user's process writes to e.g. fd 1, it's writing to a pipe that the monitor process then reads from and forwards to the bridge.
The bridge is what collects the output from the various monitor processes and outputs it formatted at the terminal. It is started inside init(), with the process forking such that the parent becomes the bridge, while the child goes on to run the user's program.
Spawning
spawn() takes a function, an argument, and resource constraints, and spawns a new process with them. This works by invoking a clean copy of the current binary with execve("/proc/self/exe",argv,envp), which, in its invocation of init(), acts slightly differently: it connects back to the preexisting bridge, and rather than returning control flow back up, it invokes the specified user function with the user argument, before exiting normally. The function pointer is adjusted relative to a fixed base in the text section.
Communication happens by creating Sender<T>s and Receiver<T>s. Creation takes a Pid, and does quite a bit of bookkeeping behind the scenes to ensure that:
- Duplex TCP connections are created and tore down correctly and opportunely to back the simplex channels created by the user.
- The resource consumption in the OS of TCP connections is proportional to the number of channels held by the user.
Pids are unique.- Each process has a single port (bound ephemerally at initialisation to avoid starvation or failure) that all channel-backing TCP connections are to or from.
- (De)serialisation can occur asynchronously, i.e. to avoid having to allocate unbounded memory to hold the result of serde's serialisation if the socket is not ready to be written to, leverage coroutines courtesy of
libfringe. - The type of a channel's message can be changed by dropping and recreating it.
Deploy
There are four main differences when running on a fabric cluster:
FabricListens on a configurable address, receiving binaries and executing them.
Fabric MasterTakes addresses and resources of the zero or more other fabric instances as input, as well as what processes to start automatically – this will almost always be the bridge.
It listens on a configurable address for binaries with resource requirements to deploy – but almost always it only makes sense for the bridge to be giving it these binaries.
BridgeRather than being invoked by a fork inside the user process, it is started automatically at fabric master-initialisation time. It listens on a configurable address for cargo deployments, at which point it runs the binary with special env vars that trigger init() to print resource requirements of the initial process and exit, before sending the binary with the determined resource requirements to the fabric master. Upon being successfully allocated, it is executed by a fabric instance. Inside init(), it connects back to the bridge, which dutifully forwards its output to cargo deploy.
cargo deploy
This is a command added to cargo that under the hood invokes cargo run, except that rather than the resulting binary being run locally, it is sent off to the bridge. The bridge then sends back any output, which is output formatted at the terminal.
How to use it
[dependencies]
deploy = "0.1.2"
extern crate deploy;
use deploy::*;
fn main() {
init(Resources::default());
println!("Hello, world!");
}
$ cargo +nightly-2018-06-10 run
3fecd01:
Hello, world!
exited: 0
Or, to run distributed: Machine 2:
cargo +nightly-2018-06-10 install fabric
fabric 10.0.0.2:9999
Machine 3:
cargo +nightly-2018-06-10 install fabric
fabric 10.0.0.3:9999
Machine 1:
cargo +nightly-2018-06-10 install fabric deploy
fabric master 10.0.0.1:9999 400GiB 34 bridge 10.0.0.1:8888 \
10.0.0.2:9999 400GiB 34 \
10.0.0.3:9999 400GiB 34
Your laptop:
cargo +nightly-2018-06-10 install deploy
rustup default nightly-2018-06-10 # cargo deploy doesn't support +version syntax yet
cargo deploy 10.0.0.1:8888 --release
833d3de:
Hello, world!
exited: 0
Rust: nightly. NB: the current nightly rustc crashes, so use known working nightly-2018-06-10 for the time being.
Linux: kernel >= 3.9; /proc filesystem; IPv4 where the address given to fabric master is bindable to by the fabric itself (this requirement could be lifted).
Arch: x86-64 (this requirement could be broadened quite straightforwardly to the x86, x86_64, aarch64, or1k that libfringe supports).
Please file an issue if you experience any other requirements.
API
Testing
Why?
Deploy forms the basis of a large-scale data processing project I'm working on. I decided to start polishing it and publish it as open source on the off chance it might be interesting or even useful to anyone else!
License
Licensed under Apache License, Version 2.0, (LICENSE.txt or http://www.apache.org/licenses/LICENSE-2.0).
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be licensed as above, without any additional terms or conditions.
Dependencies
~10MB
~185K SLoC