3 releases (breaking)
| new 0.3.1 | Apr 29, 2025 |
|---|---|
| 0.2.0 | Jun 25, 2024 |
| 0.1.11 | May 27, 2024 |
#372 in Algorithms
779 downloads per month
270KB
131 lines
A Rust implementation of the CVM Algorithm for Counting Distinct Elements
This library implements the algorithm described in
Chakraborty, S., Vinodchandran, N. V., & Meel, K. S. (2022). Distinct Elements in Streams: An Algorithm for the (Text) Book. 6 pages, 727571 bytes. https://doi.org/10.4230/LIPIcs.ESA.2022.34
The accompanying article in Quanta is here: https://www.quantamagazine.org/computer-scientists-invent-an-efficient-new-way-to-count-20240516/
What does that mean
The count-distinct problem, or cardinality-estimation problem refers to counting the number of distinct elements in a data stream with repeated elements. As a concrete example, imagine that you want to count the unique words in a book. If you have enough memory, you can keep track of every unique element you encounter. However, you may not have enough working memory due to resource constraints, or the number of potential elements may be enormous. This constraint is referred to as the bounded-storage constraint in the literature.
In order to overcome this constraint, streaming algorithms have been developed: Flajolet-Martin, LogLog, HyperLogLog. The algorithm implemented by this library is an improvement on these in one particular sense: it is extremely simple. Instead of hashing, it uses a sampling method to compute an unbiased estimate of the cardinality.
What is an Element
In this implementation, an element is anything implementing the Eq + PartialEq + Hash traits: various integer flavours, strings, any Struct on which you have implemented the traits. Not f32 / f64, however.
Ownership
The buffer has to keep ownership of its elements. In practice, this is not a problem: relative to its input stream size, the buffer is very small. This is also the point of the algorithm: your data set is very large and your working memory is small; you don't want to keep the original data around in order to store references to it! Thus, if you have &str elements you will need to create new Strings to store them. If you're processing text data you'll probably want to strip punctuation and regularise the case, so you'll need new Strings anyway. If you're processing strings containing numeric values, parsing them to the appropriate integer type (which implements Copy) first seems like a reasonable approach.
Further Details
Don Knuth has written about the algorithm (he refers to it as Algorithm D) at https://cs.stanford.edu/~knuth/papers/cvm-note.pdf, and does a far better job than I do at explaining it. You will note that on p1 he describes the buffer he uses as a data structure – called a treap – as a binary tree
"that’s capable of holding up to s ordered pairs (a, u), where a is an element of the stream and u is a real number, 0 ≤ u < 1."
where s >= 1. Our implementation doesn't use a treap as a buffer; it uses a fast HashSet with the FxHash algorithm: we pay the hash cost when inserting, but search in step D4 is O(1). The library may switch to a treap implementation eventually.
What does this library provide
Two things: the crate / library, and a command-line utility (cvmcount) which will count the unique strings in an input text file.
Installation
Binaries and installation instructions are available for x64 Linux, Apple Silicon and Intel, and x64 Windows in releases
You can also build your own if you have Rust installed: cargo install cvmcount.
CLI Example
cvmcount -t file.txt -e 0.8 -d 0.1 -s 5000
-t --tokens: a valid path to a text file
-e --epsilon: how close you want your estimate to be to the true number of distinct tokens. A smaller ε means you require a more precise estimate. For example, ε = 0.05 means you want your estimate to be within 5 % of the actual value. An epsilon of 0.8 is a good starting point for most applications.
-d --delta: the level of certainty that the algorithm's estimate will fall within your desired accuracy range. A higher confidence (e.g. 99.9 %) means you're very sure the estimate will be accurate, while a lower confidence (e.g. 90 %) means there's a higher chance the estimate may be outside your desired range. A delta of 0.1 is a good starting point for most applications.
-s --streamsize: this is used to determine buffer size and can be a loose approximation. The closer it is to the stream size, the more accurate the results.
The --help option is available.
Analysis
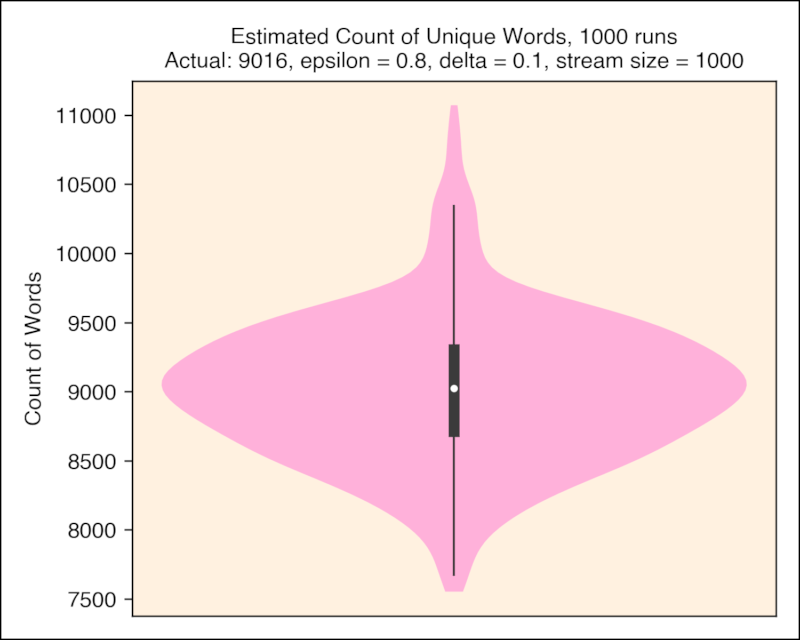
Mean: 9015.744000
Std: 534.076058
Min 7552.000000
25% 8672.000000
50% 9024.000000
75% 9344.000000
Max 11072.00000
Note
If you're thinking about using this library, you presumably know that it only provides an estimate (within the specified bounds), similar to something like HyperLogLog. You are trading accuracy for speed and memory usage!
Perf
Calculating the unique tokens in a 418K UTF-8 text file using the CLI takes 7.2 ms ± 0.3 ms on an M2 Pro. Counting 10e6 7-digit integers takes around 13.5 ms. An exact count using the same regex and HashSet runs in around 18 ms. Run cargo bench for more.
Implementation Details
The CLI app strips punctuation from input tokens using a regex. I assume there is a small performance penalty, but it seems like a small price to pay for increased practicality.
Dependencies
~3–4.5MB
~74K SLoC