14 releases
| 0.7.1 | Dec 19, 2024 |
|---|---|
| 0.7.0 | May 14, 2024 |
| 0.6.2 | Jan 14, 2024 |
| 0.6.1 | Oct 24, 2022 |
| 0.1.0 | Jan 26, 2018 |
#90 in Parser implementations
3,593 downloads per month
Used in 8 crates
(4 directly)
67KB
1K
SLoC
Bitter
Reading bits until the bitter end
![]()
![]()
![]()
Bitter reads bits in a desired endian format platform agnostically. Performance is the distinguishing feature compared to other bit readers. See benchmarks for more information.
Features
- ✔ support for little endian, big endian, and native endian formats
- ✔ request an arbitrary amount of bits (up to 64 bits) and bytes
- ✔ ergonomic requests for common data types (eg:
u8...u64,f64, etc) - ✔ fastest bit reader at multi-GiB/s throughput
- ✔ no allocations, no dependencies, and no panics
- ✔
no_stdcompatible
Quick start with Auto mode
The example below gives a good demonstration of the main API surface area to decode a 16 bit data model. It strikes a good balance between ergonomics and speed.
use bitter::{BitReader, LittleEndianReader};
let mut bits = LittleEndianReader::new(&[0xff, 0x04]);
assert_eq!(bits.bytes_remaining(), 2);
assert_eq!(bits.read_bit(), Some(true));
assert_eq!(bits.bytes_remaining(), 1);
assert_eq!(bits.read_u8(), Some(0x7f));
assert!(bits.has_bits_remaining(7));
assert_eq!(bits.read_bits(7), Some(0x02));
The read_ prefixed functions are colloquially known as "Auto mode", as one does not need to manage the underlying bits in the lookahead buffer.
Manual mode
One can unlock additional performance by amortizing internal state logic management when exploiting patterns in the encoded data. Our example from before can be rewritten to take advantage of our domain knowledge that we'll be decoding 16 bits.
use bitter::{BitReader, LittleEndianReader};
let mut bits = LittleEndianReader::new(&[0xff, 0x04]);
// ... snip code that may have read some bits
// We first check that there's enough total bits
if !bits.has_bits_remaining(16) {
panic!("not enough bits remaining");
}
// Despite there being enough data, the lookahead buffer may not be sufficient
if bits.lookahead_bits() < 16 {
bits.refill_lookahead();
assert!(bits.lookahead_bits() >= 16)
}
// We use a combination of peek and consume instead of read_*
assert_eq!(bits.peek(1), 1);
bits.consume(1);
// Notice how the return type is not an `Option`
assert_eq!(bits.peek(8), 0x7f);
bits.consume(8);
// We can switch back to auto mode any time
assert!(bits.has_bits_remaining(7));
assert_eq!(bits.read_bits(7), Some(0x02));
The refill, peek, and consume combination are the building blocks for Manual Mode, and allows fine grain management for hot loops. The surface area of Manual Mode APIs is purposely compact to keep things simple. The Auto mode API is larger as that API should be the first choice.
A major difference between Manual mode and Auto mode is that one can't peek at more than what's in the lookahead buffer. Since the lookahead buffer will vary between MAX_READ_BITS and 63 bits, one will need to write logic to stitch together peeks above MAX_READ_BITS in the endian of their choice.
Manual mode can be intimidating, but it's one of if not the fastest way to decode a bit stream, as it's based on variant 4 from Fabian Giesen's excellent series on reading bits. Others have employed this underlying technique to significantly speed up DEFLATE.
An example of how one can write a Manual mode solution for reading 60 bits:
use bitter::{BitReader, LittleEndianReader};
let data: [u8; 8] = [0xab, 0xcd, 0xef, 0x01, 0x23, 0x45, 0x67, 0x89];
let mut bits = LittleEndianReader::new(&data);
// ... snip ... maybe some bits are read here.
let expected = 0x0967_4523_01EF_CDAB;
let bits_to_read = 60u32;
bits.refill_lookahead();
let lo_len = bits.lookahead_bits();
let lo = bits.peek(lo_len);
bits.consume(lo_len);
let left = bits_to_read - lo_len;
bits.refill_lookahead();
let hi_len = bits.lookahead_bits().min(left);
let hi = bits.peek(hi_len);
bits.consume(hi_len);
assert_eq!(expected, (hi << lo_len) + lo);
The above is not an endorsement of the best way to simulate larger reads in Manual mode. For instance, it may be better to drain the lookahead first, or use MAX_READ_BITS to calculate lo instead of querying lookahead_bits. Always profile for your environment.
Unchecked mode
There's one final trick that bitter exposes that dials performance to 11 at the cost of safety and increased assumptions. Welcome to the unchecked refill API (referred to as "unchecked"), which can only be called when there are at least 8 bytes left in the buffer. Anything less than that can cause invalid memory access. The upside is that this API unlocks the holy grail of branchless bit reading.
Always guard unchecked access at a higher level:
use bitter::{BitReader, LittleEndianReader, MAX_READ_BITS};
let mut bits = LittleEndianReader::new(&[0u8; 100]);
let objects_to_read = 10;
let object_bits = 56;
let desired_bits = objects_to_read * object_bits;
let bytes_needed = (desired_bits as f64 / 8.0).ceil();
if bits.unbuffered_bytes_remaining() >= bytes_needed as usize {
for _ in 0..objects_to_read {
unsafe { bits.refill_lookahead_unchecked() };
let _field1 = bits.peek(2);
bits.consume(2);
let _field2 = bits.peek(18);
bits.consume(18);
let _field3 = bits.peek(18);
bits.consume(18);
let _field4 = bits.peek(18);
bits.consume(18);
}
} else if bits.has_bits_remaining(desired_bits) {
// So have enough bits to read all the objects just not
// enough bits to call the unchecked lookahead API everytime.
assert!(false);
} else {
// Not enough data.
assert!(false);
}
All three modes: auto, manual, and unchecked can be mixed and matched as desired.
no_std crates
This crate has a feature, std, that is enabled by default. To use this crate
in a no_std context, add the following to your Cargo.toml:
[dependencies]
bitter = { version = "x", default-features = false }
Comparison to other libraries
Bitter is hardly the first Rust library for handling bits. nom, bitvec, bitstream_io, and bitreader are all crates that deal with bit reading. The reason why someone would choose bitter is speed.
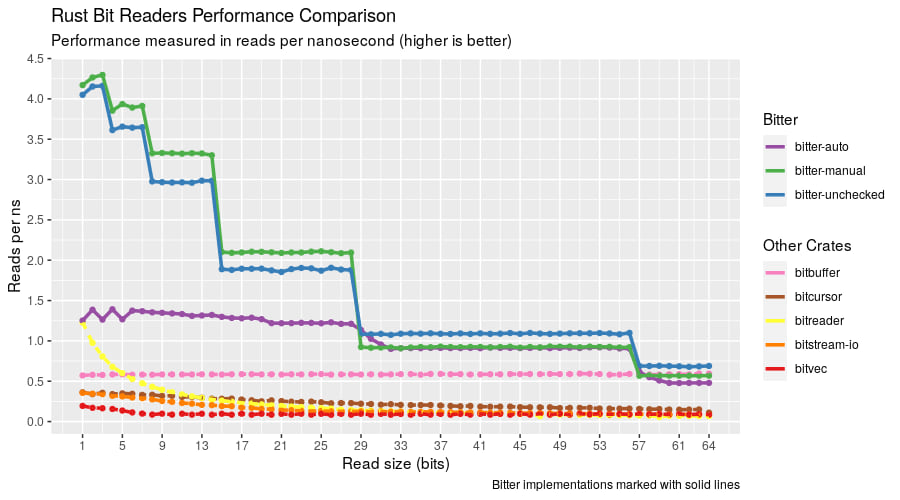
Takeaways:
- Bitter is the fastest Rust bit reading library even using the safest Auto API
- Chaining small bit reads with the manual or unchecked API allows Bitter to issue multiple read commands per nanosecond
- At large read sizes, differences between the bitter APIs and the next fastest (bitbuffer) start to diminish.
Benchmarking
Benchmarks are ran with the following command:
(cd compare && cargo clean && cargo bench)
find ./compare/target -path "*bit-reading*" -wholename "*/new/raw.csv" -print0 \
| xargs -0 xsv cat rows > assets/bitter-benchmark-data.csv
And can be analyzed with the R script found in the assets directory. Keep in mind, benchmarks will vary by machine